Key deliverable
RAG System Development
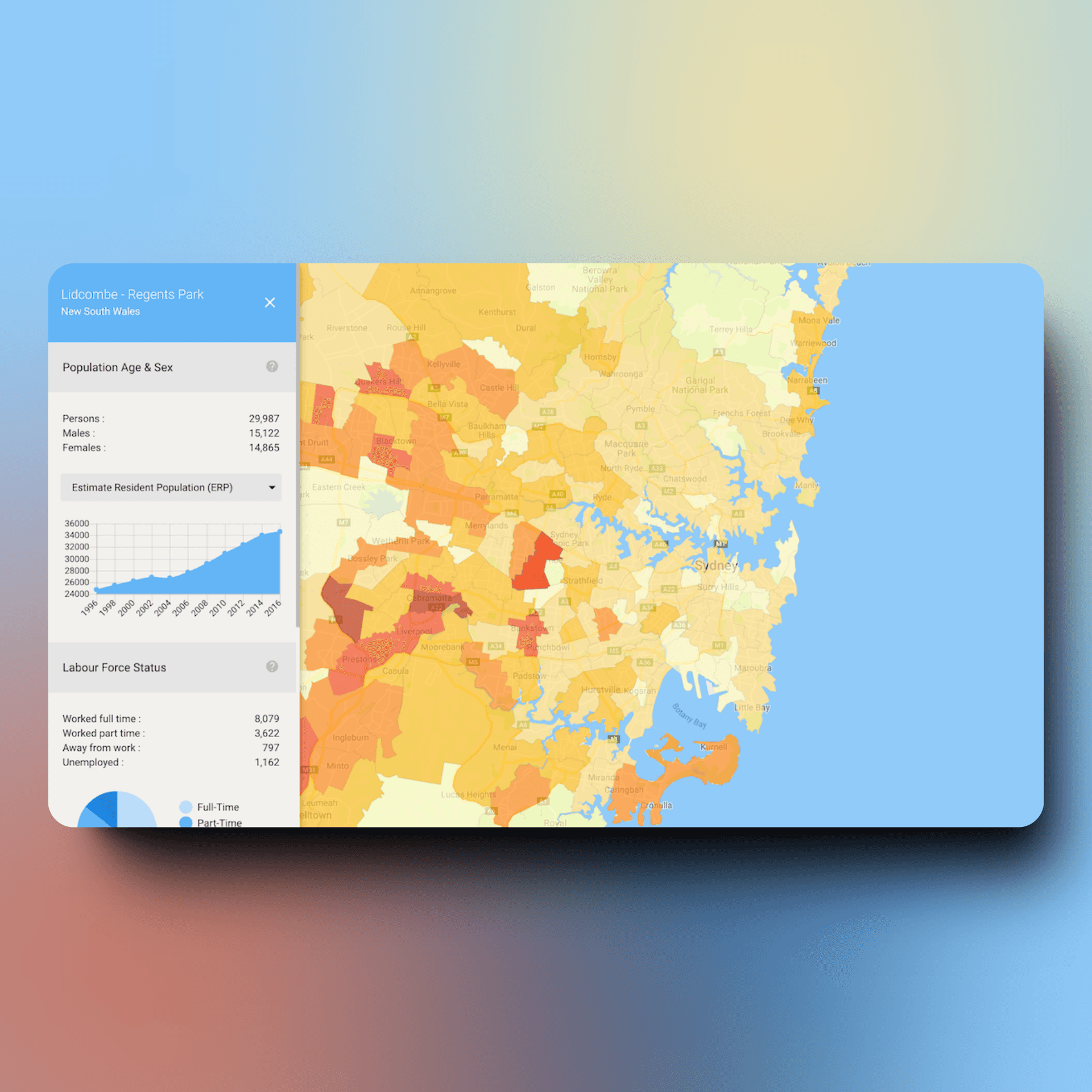
Build Retrieval-Augmented Generation systems that ground AI responses in your proprietary data, eliminating hallucinations and ensuring accurate, contextual answers from documents, databases, and knowledge bases.
- Document ingestion pipeline processing PDFs, Word docs, spreadsheets, wikis, and web pages with intelligent chunking strategies optimized for semantic retrieval
- Vector database implementation using Pinecone, Weaviate, Qdrant, or Milvus for fast semantic search across millions of document chunks
- Hybrid search combining semantic similarity (vector search) with keyword matching (BM25) and intelligent reranking for optimal retrieval accuracy
- Context-aware retrieval using metadata filtering, query expansion, and relevance scoring to surface the most pertinent information