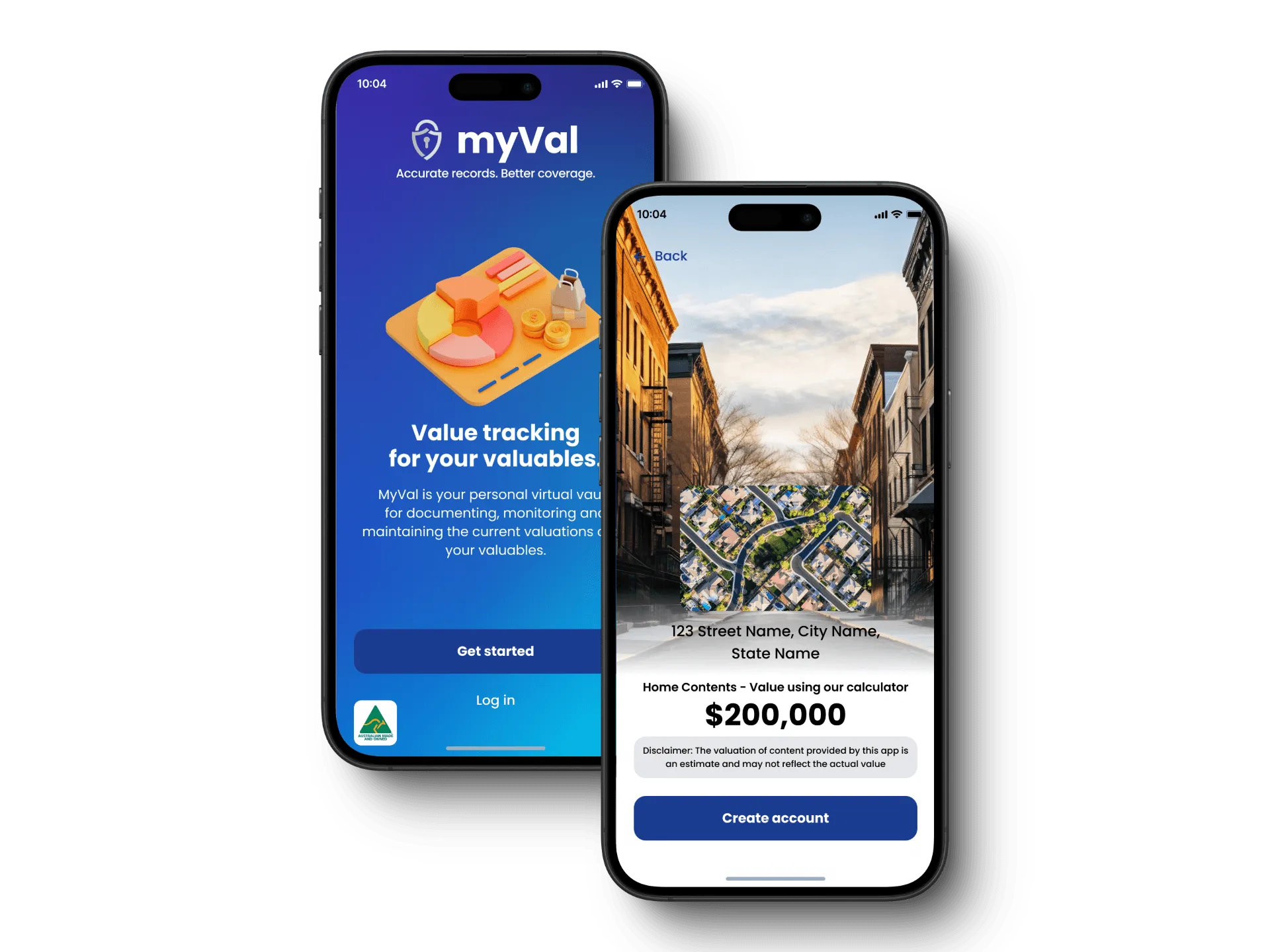
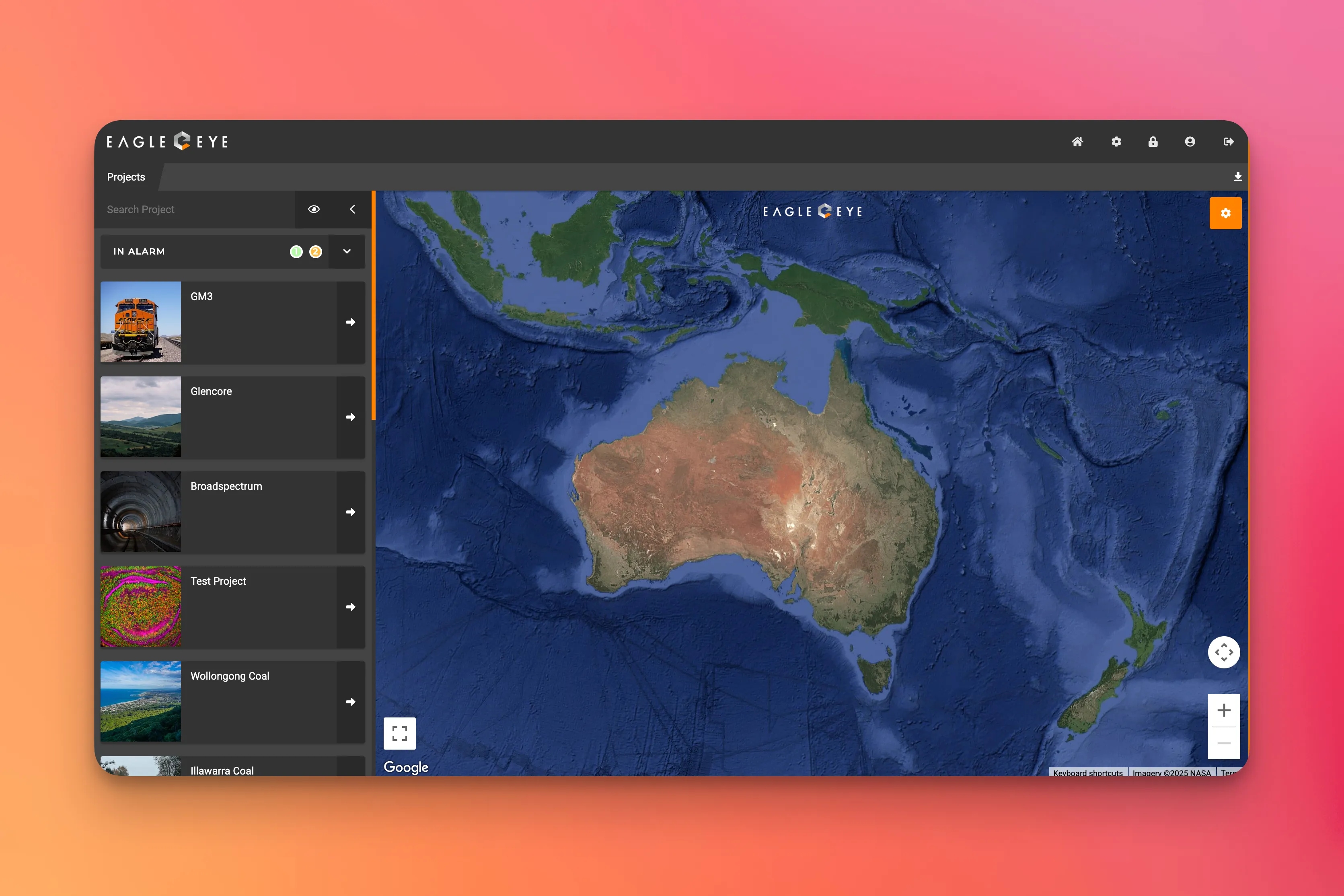
Key deliverable
Infrastructure d'Observabilité
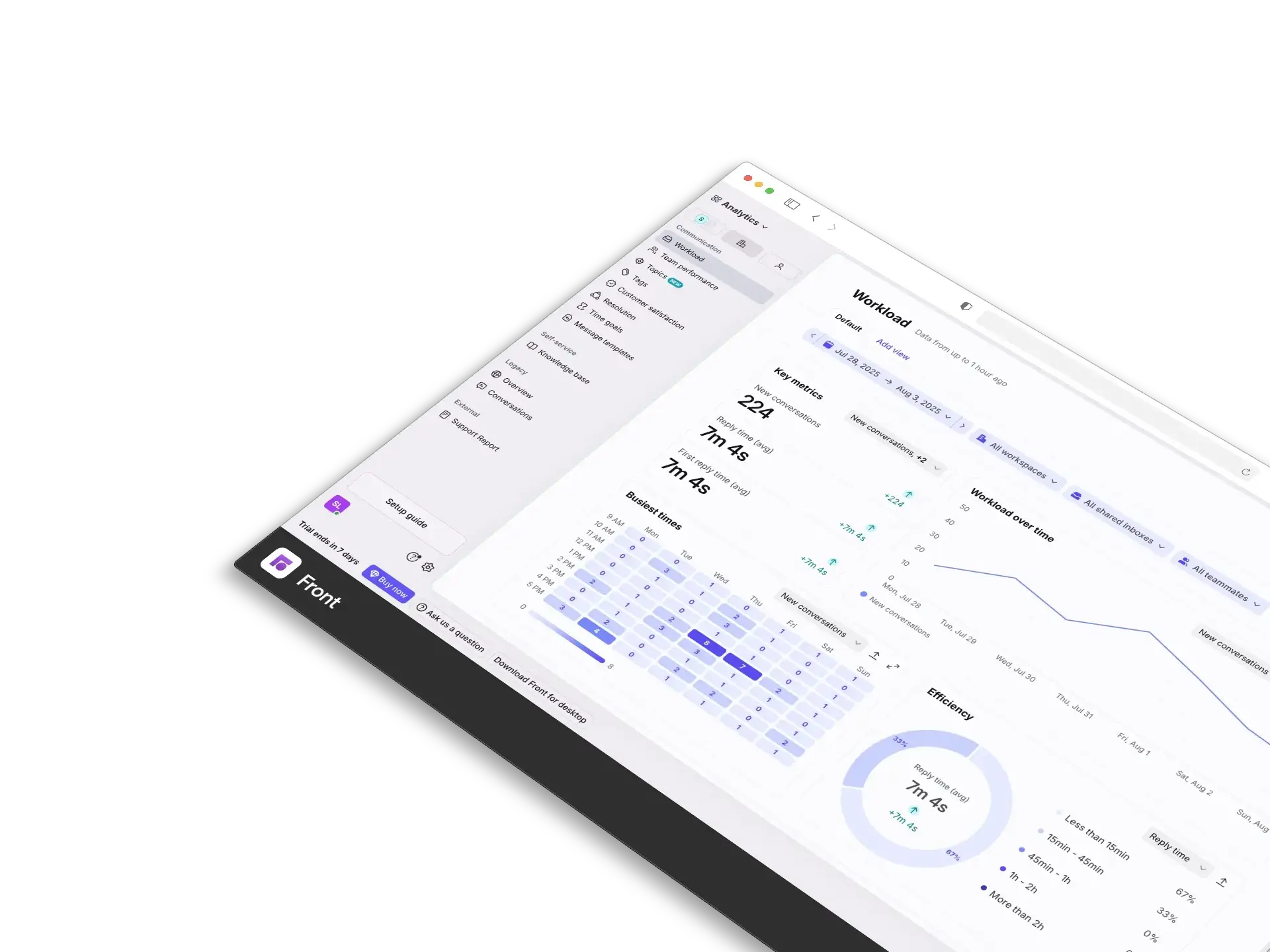
Obtenez une visibilité complète sur le comportement du système, les dépendances et les performances grâce à une observabilité complète (métriques, logs, traces).
- Tableaux de bord de métriques en temps réel affichant la santé du système, l'utilisation des ressources et les performances de l'application
- Infrastructure de journalisation centralisée agrégeant les journaux de tous les services et composants d'infrastructure
- Traçage distribué pour visualiser les flux de requêtes entre les microservices et identifier les goulots d'étranglement
- Métriques personnalisées et instrumentation pour les flux de travail critiques pour l'entreprise et les parcours utilisateur